59: Find the tipping point in your user research
I bet you’ve found yourself in this situation. You’re trying to get your head around the main user problem your new product is going to solve. The thing is, for every question you try to answer, several more questions arise.
The more I know, the less I understand1
On a recent product I was helping with, we were trying to make it easier for academics to exchange information with each other. “Simple,” everyone thought to begin with, “just use Dropbox.” And for some users sharing certain types of information, Dropbox was probably the best answer.
But as we delved deeper into our user research, we realised that there was much more to it. Some users needed to exchange snapshots of very large data sets – a sequenced genome, for example – so synchronizing the files to and from Dropbox would take far too long to be useful when needed.
Similarly, some data were particularly sensitive and needed to remain not just on UK servers, but within servers owned by the university. Dropbox wasn’t the answer here either.
It was like our user problem was a fractal – the more closely we examined it, the more complicated it became.
When this happens to you, it can feel overwhelming and increasingly difficult to gauge whether you’re making progress any more. Couple this with a bit of pressure from senior management to deliver something tangible and it’s extremely tempting to lose heart with research and build something based only on what you’ve found out so far.
To stop too soon is a mistake.
You’ve not yet reached the tipping point where you know enough about the problem to set about trying to solve it.
You gotta go there to come back2
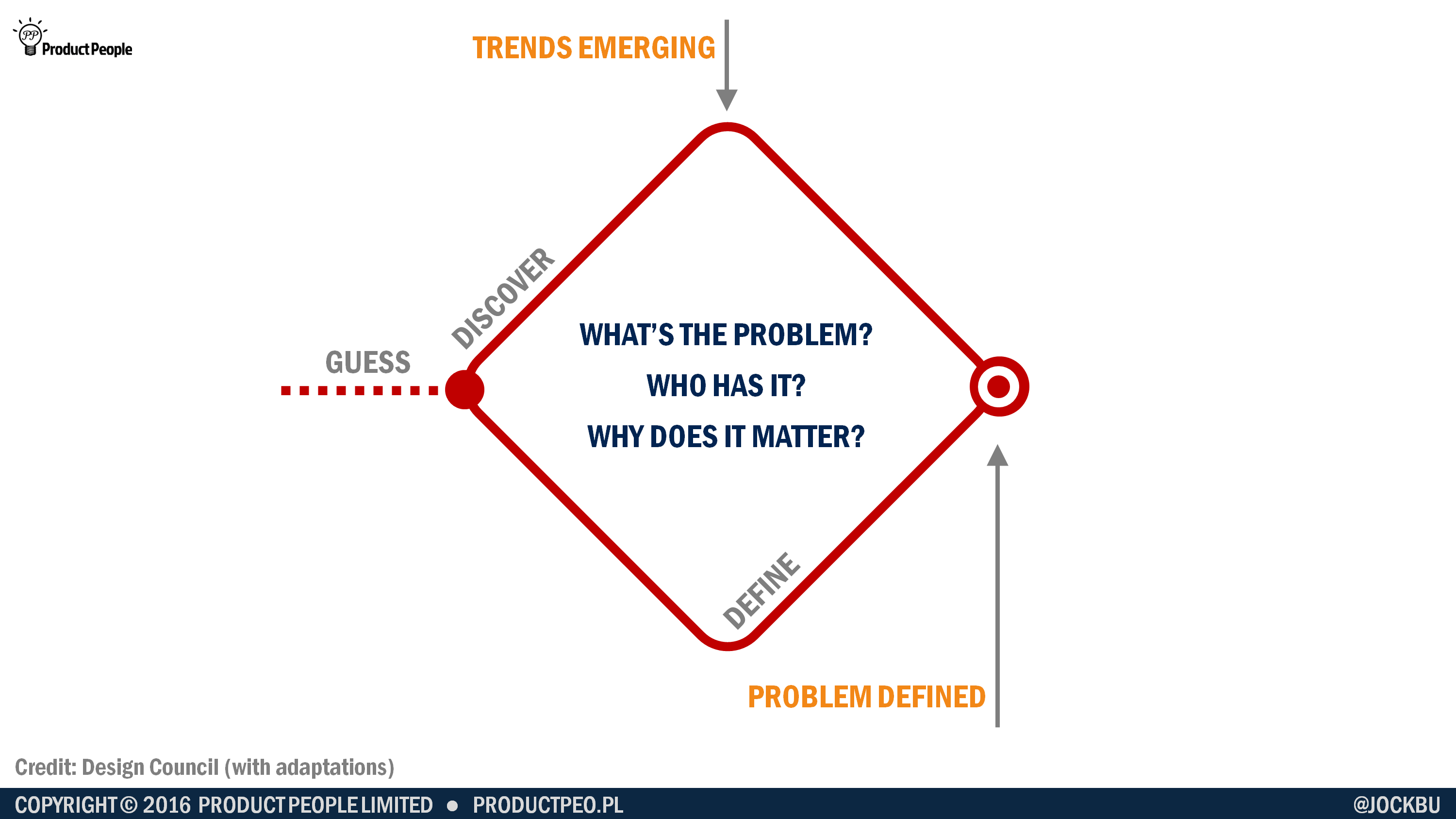
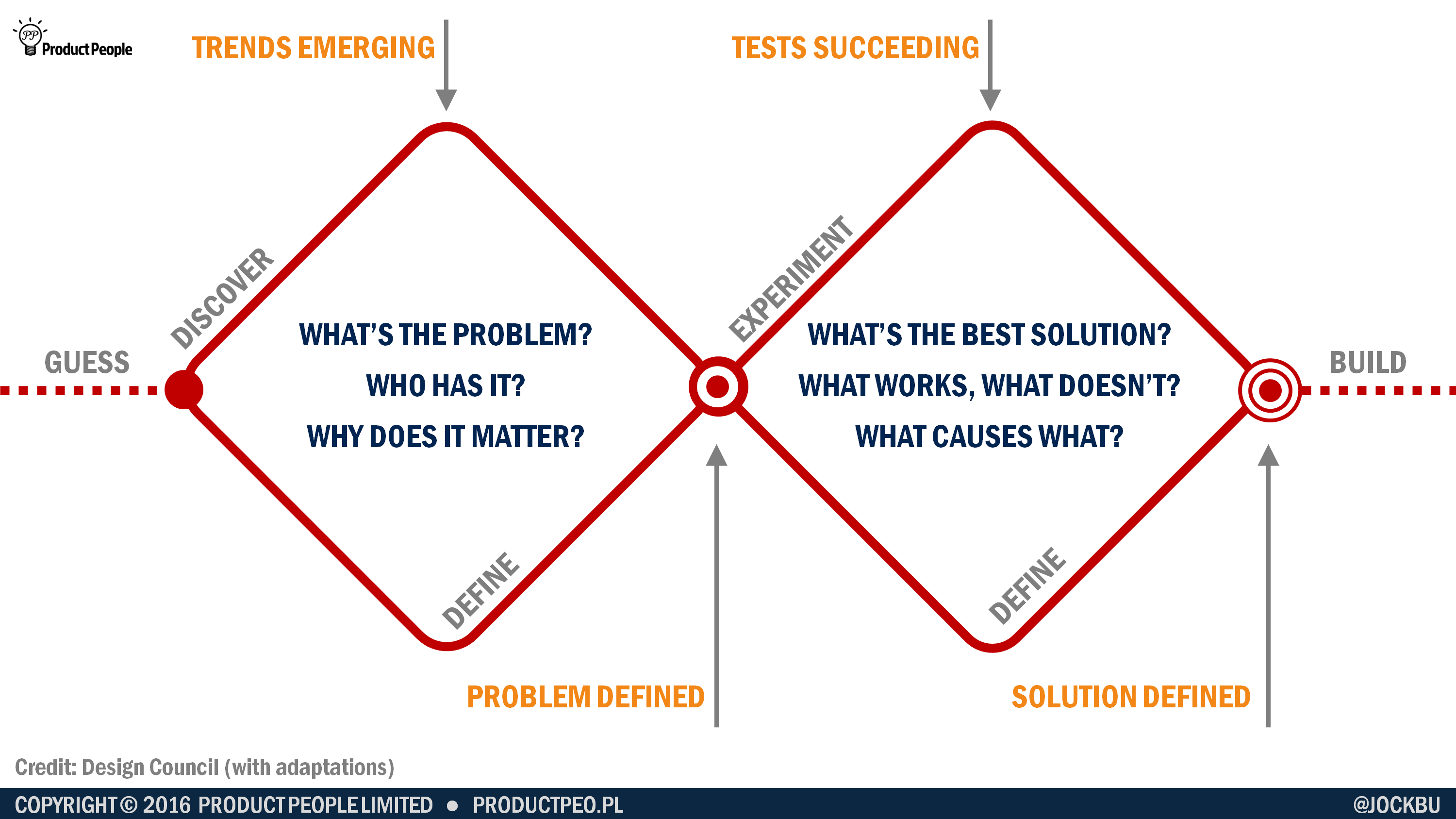
Discovery is where you set out to understand the problem, who has it, the causes of the problem, and why solving the problem matters. You can think of the first part of discovery as being divergent – each question you ask uncovers several more questions to answer. For some, this can be the disheartening bit, as they realise how complex the problem is, and how little they actually know about it.
For others this first, divergent part of discovery is extremely rewarding: every question answered reveals another piece of the puzzle and increases the team’s understanding of the problem. This knowledge helps you to decide whether it’s feasible to solve the entire problem as originally intended, or whether you need to break it down and focus in on a specific aspect to begin with – perhaps a subset of the users, or one part of what you now realise is a connected set of problems.
Then there comes the tipping point. You’ll know you’ve reached this point when you start to see trends emerging. By now, you’ll have spoken to enough users, performed enough desk research, and run enough experiments to see certain patterns. At this point, your tests of your understanding of the problem will start to come back with much greater success.
In my Dropbox project, this was the point at which we could confidently play back to our users what we’d learned about them and their file sharing needs. Now our user interviews were less about asking what they did and why, and more about checking with them what we already understood.
After the tipping point, your understanding of the problem solidifies until you have a pretty robust definition of the problem, who has it, what causes it, and why solving it matters. (But you’ll never know everything.)

Then you embark upon figuring out the solution to the problem you now understand. And just like before, you and your team start with (at best) hunches of what might solve the problem. You have to diverge again before you reach the second tipping point and start to home in on the right solution.
Some organisations, like the UK’s Government Digital Service and other digital services, call this part of the process alpha.
Again, it’s tempting to jump on the first plausible solution that appears. It’s unlikely that you will hit the best possible solution first, so keep your solution experiments, cheap, short and throwaway. You are not building the product for real yet.
When to build for real #
Only when you’ve tried out several possible solutions, established what bits work (which you keep) and what bits don’t (which you discard), can you decide what you’re going to build for real – that is: to scale; with the right choices of technology for long-term support; and secure and robust enough for a real-life user base.
The build should then be relatively quick because you and your team already know what you’re going to build, and are confident that it’s going to solve the problem.
Notes #
- Paul Weller, The Changingman ↩
- Stereophonics, You Gotta Go There To Come Back ↩
Read more from Jock

The Practitioner's Guide To Product Management
by Jock Busuttil
“This is a great book for Product Managers or those considering a career in Product Management.”
— Lyndsay Denton
Jock Busuttil is a product management and leadership coach, product leader and author. He has spent over two decades working with technology companies to improve their product management practices, from startups to multinationals. In 2012 Jock founded Product People Limited, which provides product management consultancy, coaching and training. Its clients include BBC, University of Cambridge, Ometria, Prolific and the UK’s Ministry of Justice and Government Digital Service (GDS). Jock holds a master’s degree in Classics from the University of Cambridge. He is the author of the popular book The Practitioner’s Guide To Product Management, which was published in January 2015 by Grand Central Publishing in the US and Piatkus in the UK. He writes the blog I Manage Products and weekly product management newsletter PRODUCTHEAD. You can find him on Mastodon, Twitter and LinkedIn.
Leave a Reply